Projet de fin d’étude
Pour l’obtention du diplôme d’ingénieur d’Etat en Informatique

Ecole nationale supérieure d'informatique
Le 06/07/2020 ESI ex INI, AlgerApprentissage automatique pour la détection d’anomalies dans un réseau Iot
Réalisé par Mahamdi Mohammed
Encadré par Dr. Meziani Lila
2019/2020
Le Plan
- Introduction (Contexe, Problématique, Objectifs)
- Iot
- Sécurité de l'Iot
- Apprentissage automatique
- Travaux existants
- Solution proposée
- Réalisation
- Tests et Résultats
- Conclusion et perspectives
1. Introduction (contexe)
L’Internet des objets a pour objectif de permettre aux différents objets de se connecter n'importe quand, n'importe où en utilisant n'importe quel chemin et n'importe quel service. L’Internet n’a jamais connecté autant de systèmes informatiques qu’aujourd’hui, et le nombre des objets connectés est en croissance.
Ces objets n’intégrant que rarement des mécanismes de protection contre les attaques. Donc la sécurité de leurs utilisateurs, qu’ils soient des individus ou des entreprises est en menace.
1. Introduction (Problématique)
La mise en place d’une solution de sécurité applicable à l’ensemble des objets intelligents est très difficile à cause de variétés des protocoles, différence des capacités hardware et l’absence de mises à jour par les constructeurs dans la majorité des cas.
Les travaux effectués en termes de détection d’intrusion se concentrent essentiellement sur des analyses du flux réseau, puisqu’il n’y a pas besoin de considérer les ressources matérielles des objets ni même les applications qui sont exécutées dessus.
1. Introduction (Objectif)
Afin de répondre à la problématique posée, une solution doit être proposée tout en répondant à cet objectif:
- Proposer une solution pour la détection et la classification des attaques dans un réseau Iot en utilisant des techniques d’apprentissage automatique.
2. Iot
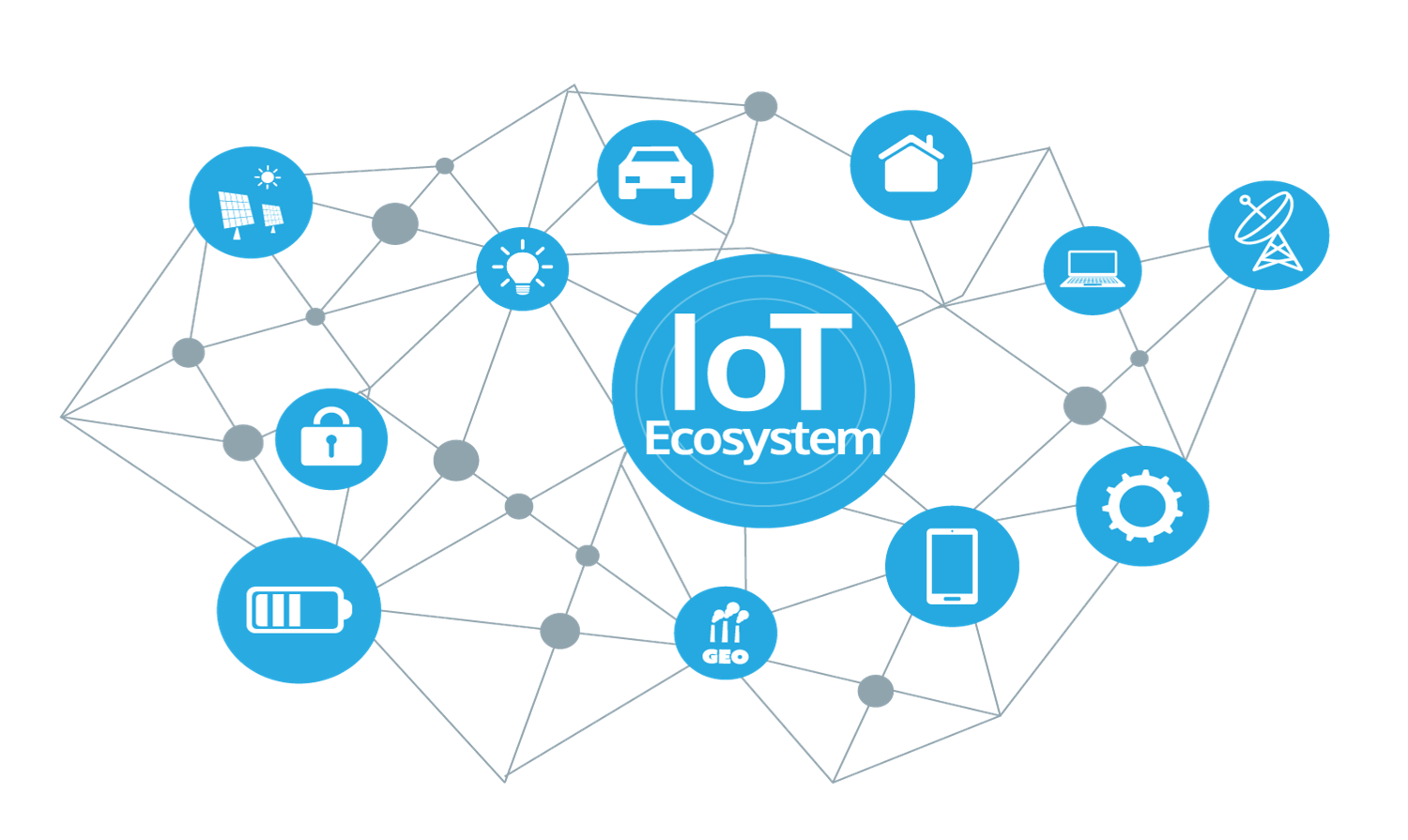
2. Iot
Les caractéristiques de L’Iot
- Inter connectivité
- Hétérogénéité
- Le changement dynamiques
- L’énorme échelle
- Connectivité
- Sécurité
- Les services liés aux objets
2. Iot: L’Architecture de L’Iot
L’Architecture de L’Iot
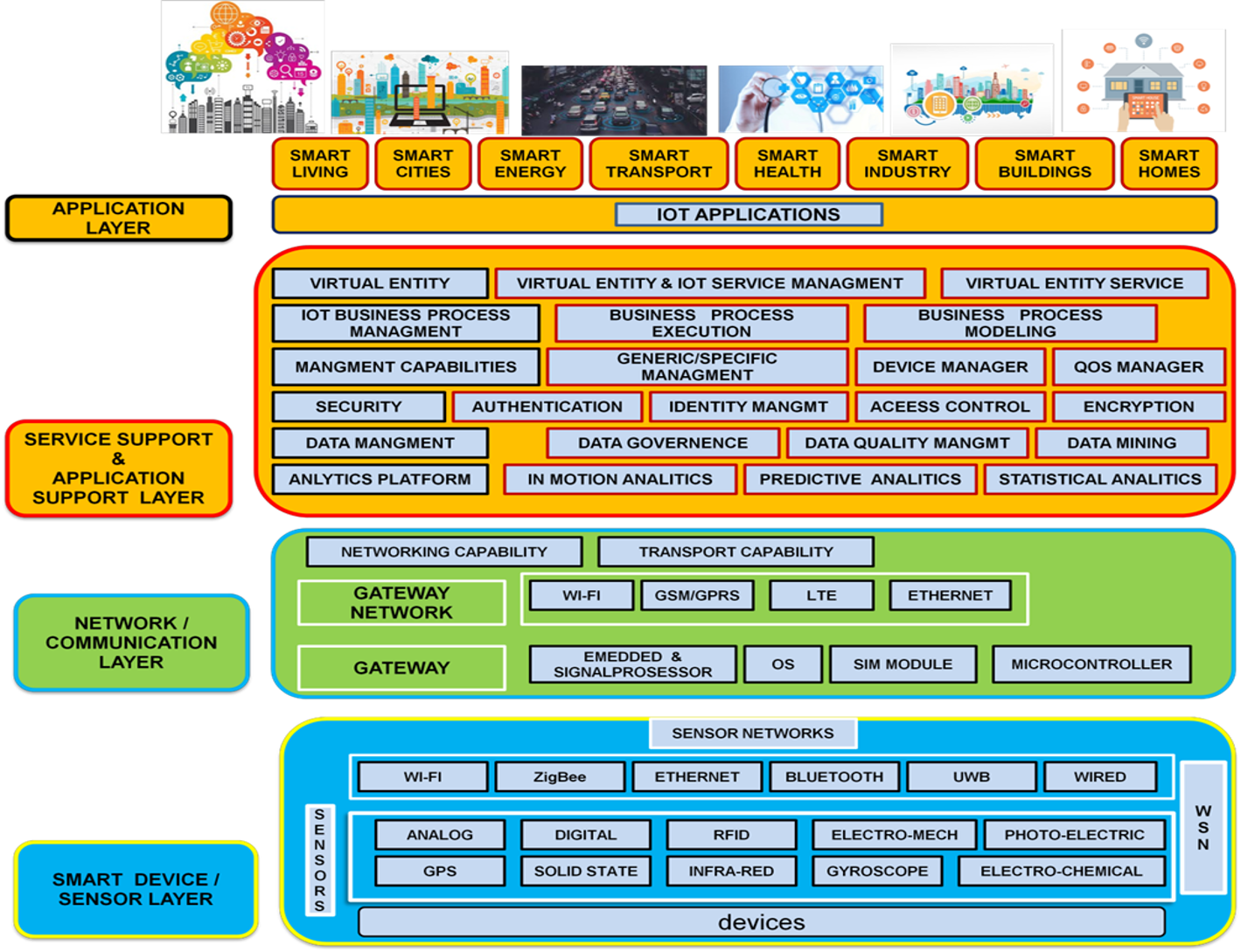
2. Iot
Les technologies de L’Iot
- Les technologies qui permettent aux objets d’acquérir des connaissances contextuelles.
- Les technologies qui permettent à ces objets de traiter ces informations.
- Les technologies pour améliorer la sécurité et la confidentialité.
3. Sécurité de l'Iot
Les anomalies caractérisant les réseaux Iot
- Injection : Exploitation d'une vulnérabilité existant pour injecter un code malicieux.
- Flooding : Provoquer une interruption ou une suspension des services.
- Impersonation : (L’emprunt d’identité) prend la forme d’un clonage de périphérique, usurpation d’adresse, accès non autorisé.
3. Sécurité de l'Iot
Les contres mesures
- Antivirus
- Pare-feu
- Les IDS : Appareil ou une application qui surveille un réseau ou des systèmes pour détecter toute activité malveillante.
4. apprentissage automatique

4. Apprentissage automatique
Intelligence artificielle Vs apprentissage automatique Vs apprentissage approfondie
4. Apprentissage automatique
Les types d’apprentissage
A. L'apprentissage supervisé
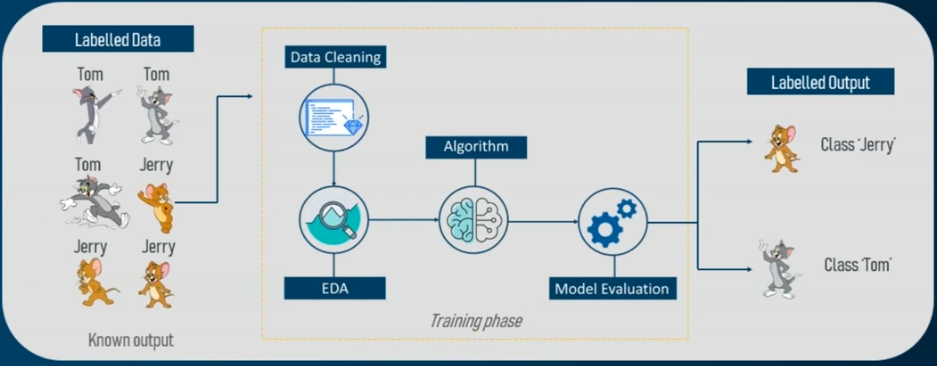
4. Apprentissage automatique
Les types d’apprentissage
B. L'apprentissage non-supervisé
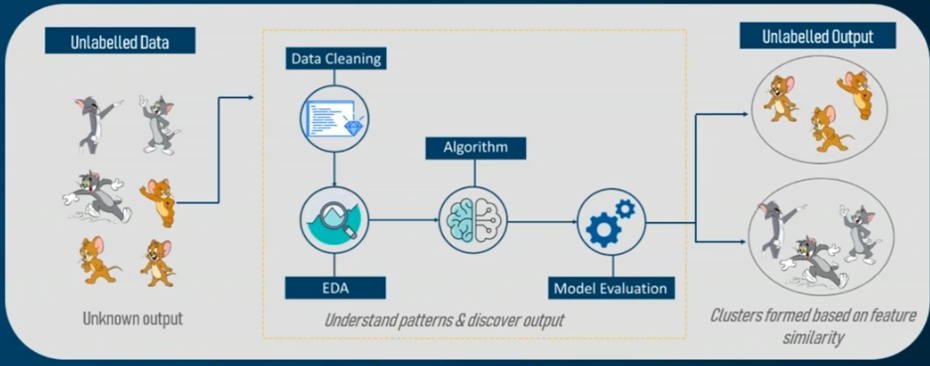
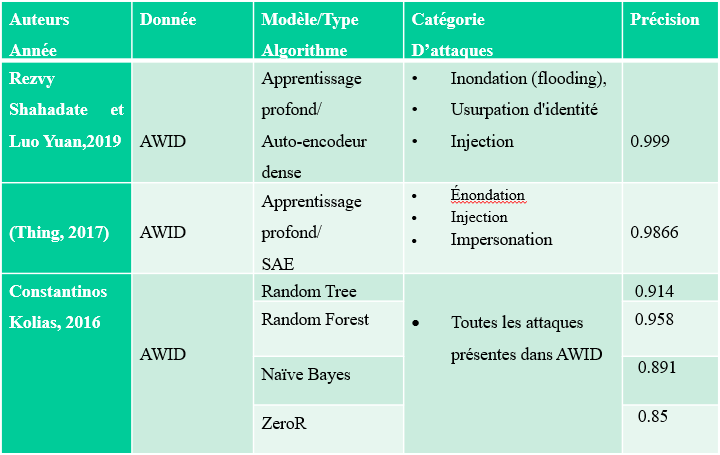
5. Les travaux existants
Nous avons sélectionné les solutions qui ont utilisé le même jeu de données pour qu'on puisse les commparer
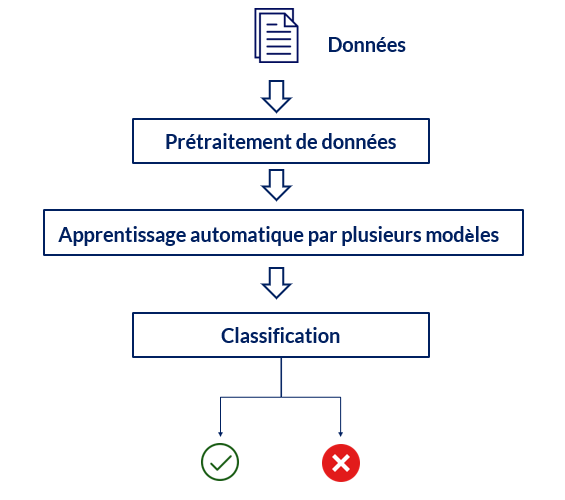
6. La solution proposée
Architecture globale
6. La solution proposée
Pré-traitement
- Remplacer les colonnes de type chaînes de caractère par une colonne de valeurs catégorielles.
- Remplacer les données manquantes dans une colonne avec la médiane.
- Transformer les données en une trame de données entièrement numérique.
- La normalisation.
6. La solution proposée
L'entraînement
Les algorithmes d’apprentissage
- Naive Bayes
- Random Forest
- XGBoost
6. La solution proposée
Les algorithmes d’apprentissage
Arbre de décision ou Decision Tree
L'idée derrière un arbre de décision est de rechercher une paire de valeur-variables dans l'ensemble d'apprentissage et de le diviser de manière à générer les meilleurs deux sous-ensembles enfants. L'objectif est de créer des branches et des feuilles sur la base d'un critère de fractionnement optimal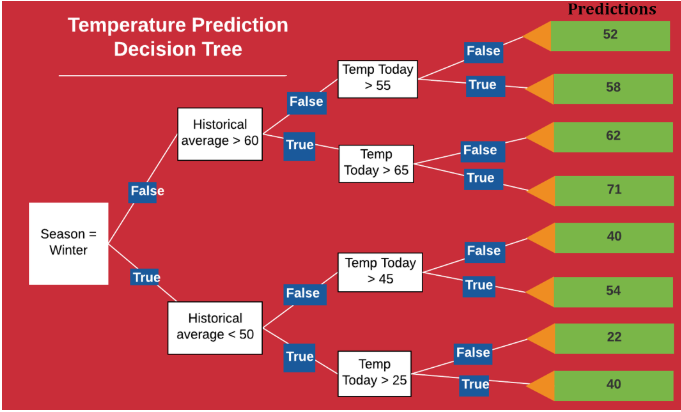
6. La solution proposée
Les algorithmes d’apprentissage
Random Forest
Un grand nombre de modèles (Decision Trees) relativement non corrélés fonctionnant en comité surclasseront n'importe lequel des modèles constitutifs individuels.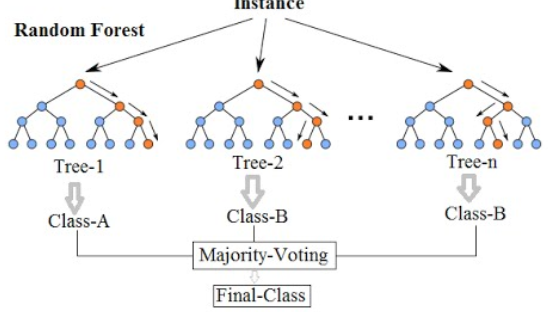
7. Conception et réalisation
Présentation du jeu de donnéest
AWID (AEGEAN WI-FI INTRUSION)DATASET
AWID site web
 AWID est le premier ensemble de données accessible au public qui respecte le protocole réseau
802.11
AWID est le premier ensemble de données accessible au public qui respecte le protocole réseau
802.11
7. Conception et réalisation
Le nombre d’enregistrements pour chaque classe dans le jeux de données AWID-CLS-R| La classe | Nombre d’enregistrements dans AWID-CLS-R-Trn | Nombre d’enregistrements dans AWID-CLS-R-Tst |
|---|---|---|
| Flooding | 48484 (2.7 %) | 8097 (1.407 %) |
| Impersonation | 48522 (2.702 %) | 20079 (3.488 %) |
| Injection | 65379 (3.641 %) | 16682 (2.898 %) |
| Normal | 1633190 (90.956 %) | 530785 (92.207 %) |
7. Conception et réalisation
Sélection d'attributs
- La sélection d’attributs améliore la généralisation, la performance et réduit le coût de calcul du classificateur.
- Donc les caractéristiques sélectionnées en haut des arborescences sont en général plus importantes.
- L'algorithme Random forest peut attribuer une importance à chaque colonne de l'ensemble de données.
- On peut sélectionner les colonnes qui ont une importance superieur a un seuil donné
7. Conception et réalisation
Sélection d'attributs
Pour réduir la dimension des données, et accelerer la classification, on a choisi 4 ensembles
| L'ensemble | La dimension | Comment il a été construit |
|---|---|---|
| Ensemble 1 | 153 | En prenant toutes les colonnes sauf celles qui ont un taux de valeur manquantes égale à 1. |
| Ensemble 2 | 9 | En choisissant les 9 plus importantes colonnes dans le modèle généré par l’algorithme Random Forest avec un seul estimateur. |
| Ensemble 3 | 21 | En choisissant les 21 plus importantes colonnes dans le modèle généré par l’algorithme Random Forest avec 100 estimateurs. |
| Ensemble 4 | 18 | En choisissant les colonnes qui ont une importance plus de 0.03 dans le modèle généré par l’algorithme Random Forest avec 200 estimateurs |
7. Conception et réalisation
Environnement technique

8. Résultats
Métriques d'évaluation
Nous avons choisi les mesures d'évaluation suivantes :
- La précision : Il s'agit du rapport entre le nombre de prédictions correctes et le nombre total
d'échantillons d'entrée.
précision = TP / ( TP + FP ) - F1-score = 1 / (précision -1 + sensibilité -1 )
- Recall = TP / ( FN + TP )
- AUC : est souvent utilisée comme mesure de la qualité des modèles de classification.
8. Résultats
Random Forest
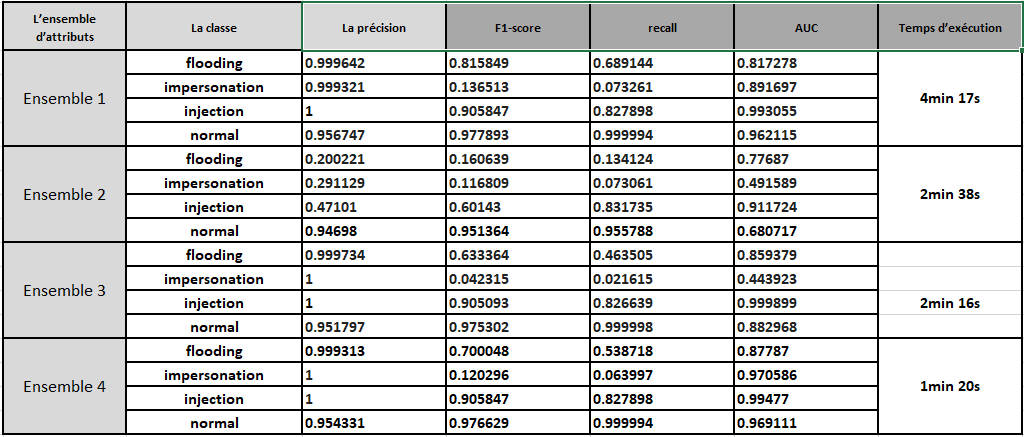
Il est clair que l'ensemble 4 est le sous-ensemble dont les fonctionnalités sont les plus importantes. Il donne presque les mêmes résultats que l'ensemble avec tout les attributs.
8. Résultats
Random Forest : ROC
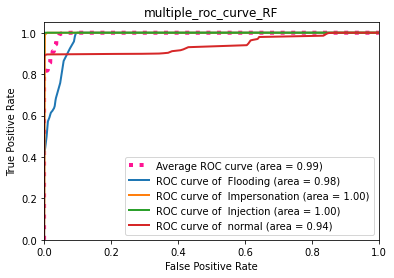

le classifieur Random Forest donne une très bonne séparation entre les classes, et il est très performant.
8. Résultats
Naive-bayes
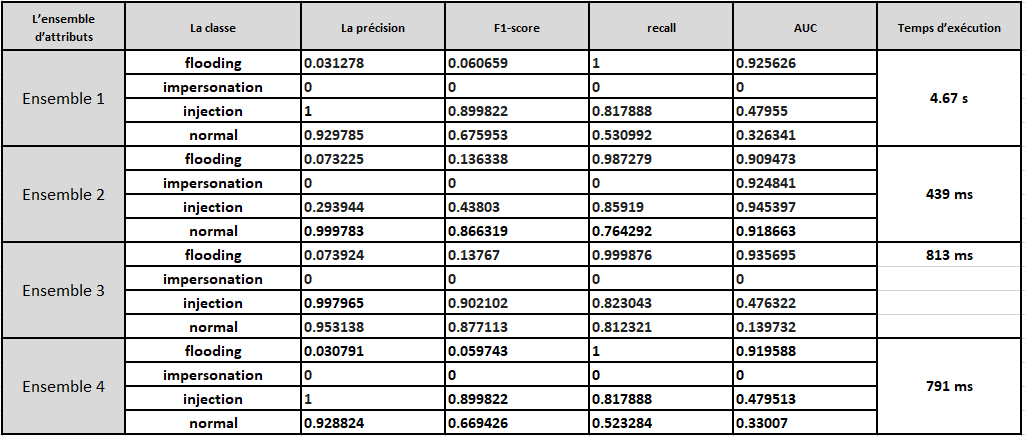
L'algorithme NaiveBayes ne prédit pas l'attaque de type impersonation, et sa précision de détecter l'attaque flooding est très faible.
8. Résultats
Naive-bayes : ROC
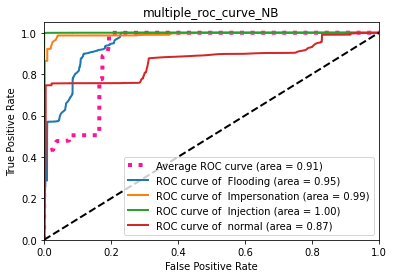
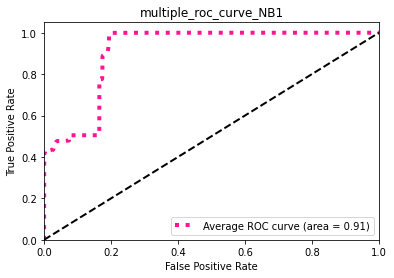
Ce classifieur ne donne pas une bonne séparation entre les classes, el il n’est pas efficace dans la détection.
8. Résultats
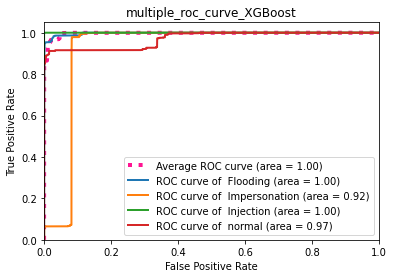
XgBoost
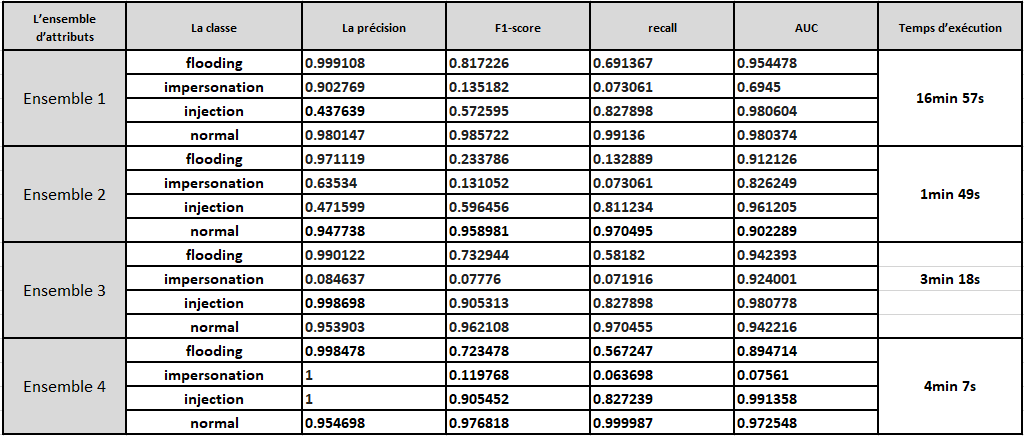
L'algorithmes XGboost détecte les deux catégories : le flux normal et l'attaque impersonation avec une précision de 1
8. Résultats
XGBoost : ROC
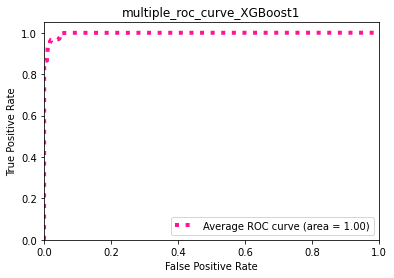
ce classifieur est très précis et performant, il donne une très bonne séparation entre les classes.
8. Résultats
ROC de tous les algorithme
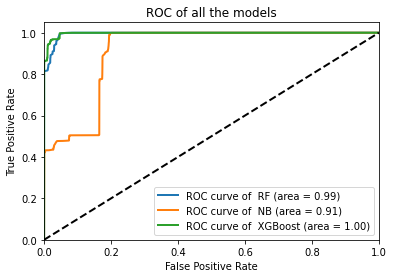
- A Partir de ce graphe, la courbe ROC du modèle naïf bayes indique que ce modèle est moins capable de distinguer entre les classes par rapport aux deux autres modèles RF et XGBOOST, ce qu’est vrai car ce modèle est incapable de détecter les attaques de type impersonation.
- La courbes ROC des deux modèles Random Forest et XGBoost sont presque identiques, elles sont très proche du coin supérieur gauche, ce qui indique une meilleure performance.
8. Résultats
Autres résultats
- L'algorithme KNN ne produit pas de bons résultats
- L'exécution de l'algorithme SVM est très longue.(plus de 5 heures)
- Vu que les faux positifs et les faux négatifs ont un coût similaire donc La précision fonctionne mieux comme une métrique d'évaluation. Donc, comme résultat final de ce projet, l’algorithme Random Forest est le meilleur algorithme pour la classification des attaques dans le dataset AWID.
Conclusion et perspectives
* Nous avons réalisé des modèles basés sur d’apprentissage machine pour la classification et la
détection des attaques. Une comparaison de ces modèles en termes d'efficacité est fournie pour
sélectionner la meilleure approche pour résoudre la problématique.
* D'après les tests, le classifieur Random Forest donne de très bons résultats.
Conclusion et perspectives
Perspectives
Plusieurs perspectives d’évolution peuvent être envisagées, le travail réalisé peut être complété et amélioré en ajoutant les fonctionnalités suivantes :
- Entrainer les modèles sur un dataset qui contient plusieurs catégories d’attaques.
- Implémenter cette solution sur un IDS pour assurer une détection d’intrusions en temps réel.